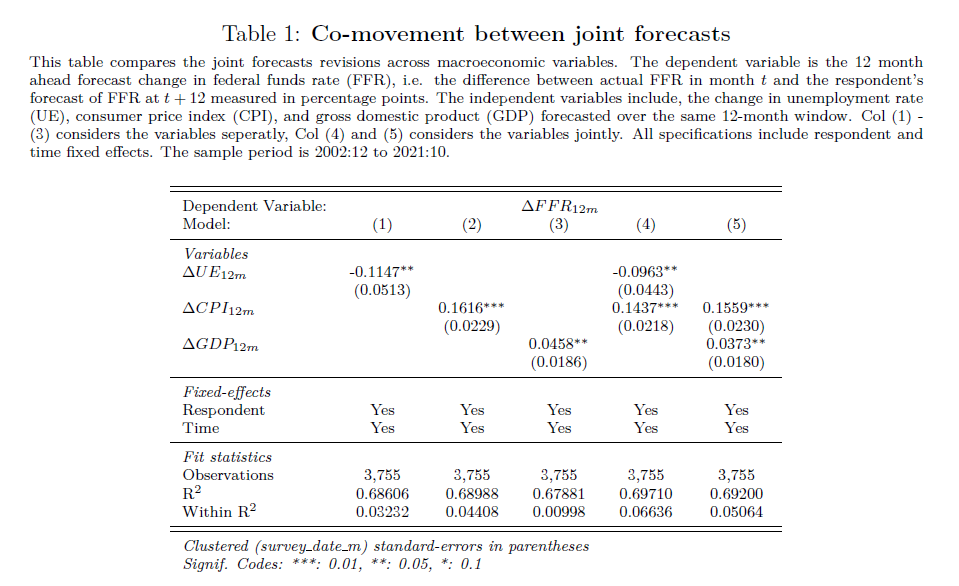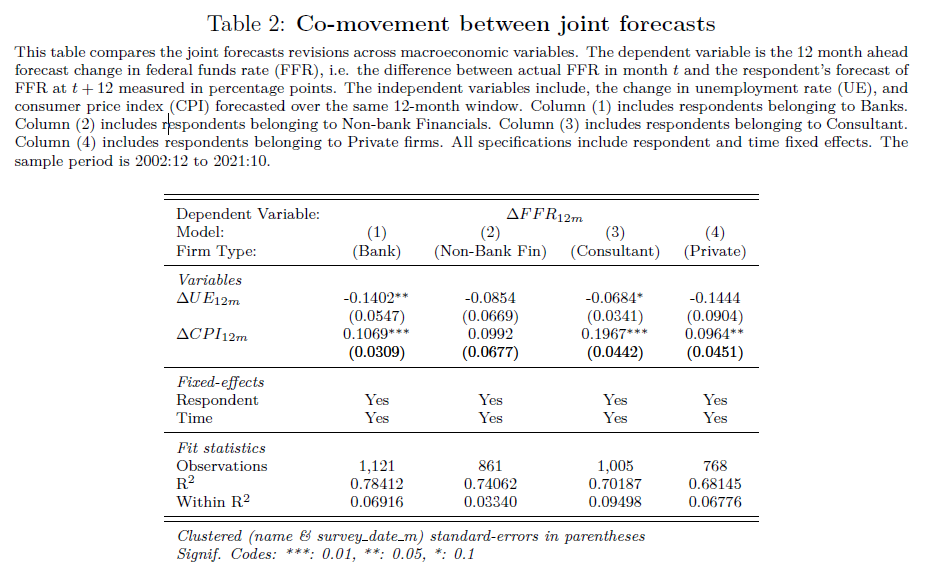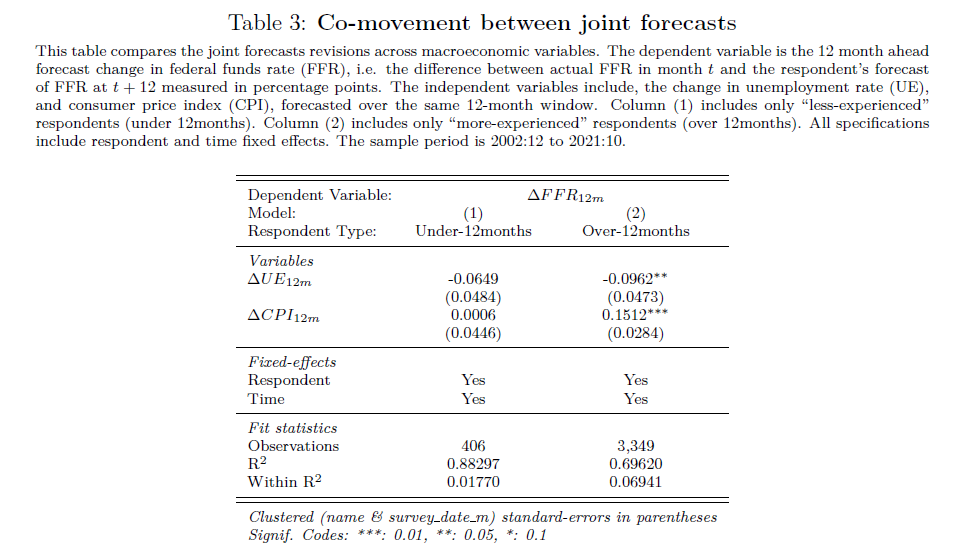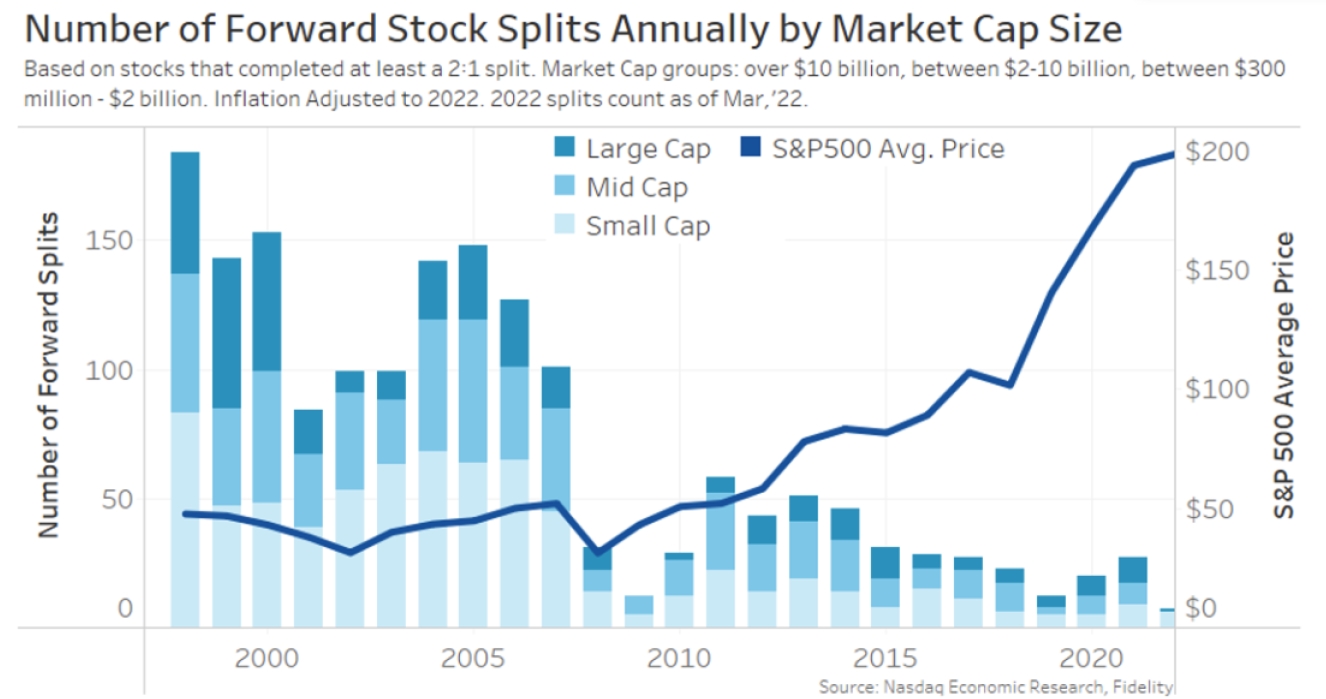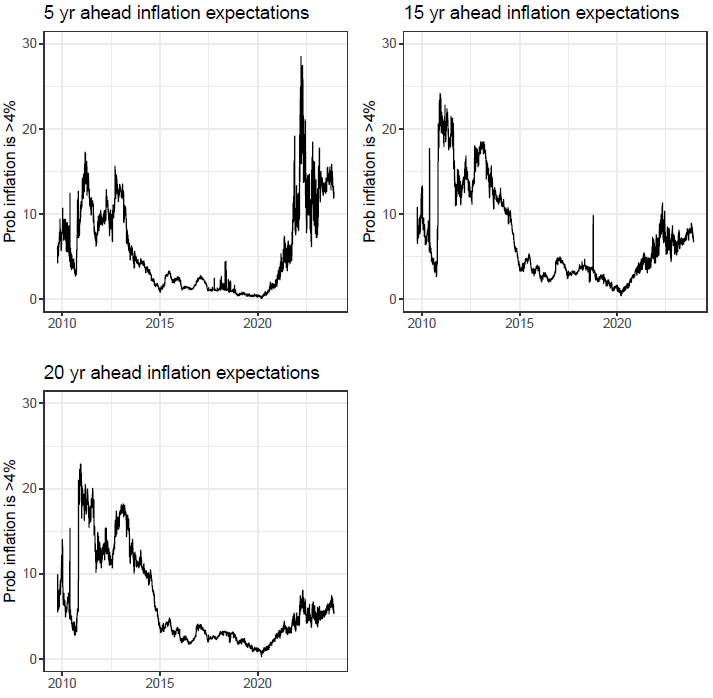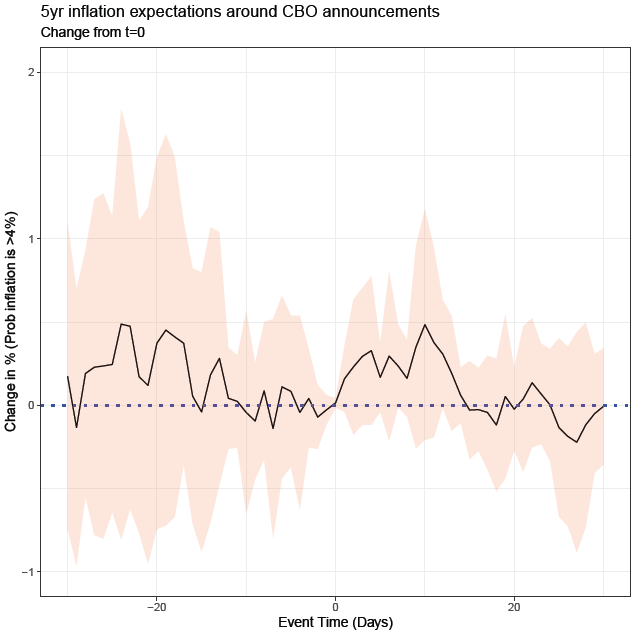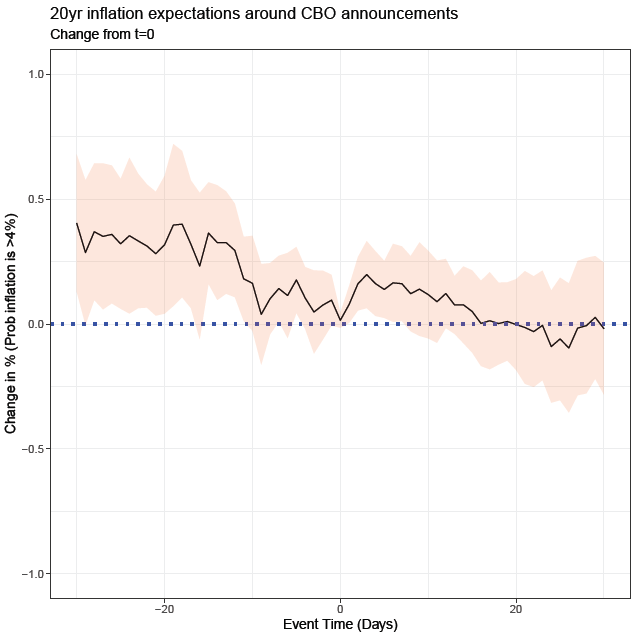
Lets look at two examples. Example 1, a game of Russian Roulette. Imagine a game where one bullet is loaded into a six-chamber gun. If you play, and the barrel lands on an empty chamber, you win $1million. If the barrel lands on the chamber with a bullet, you die. Now let’s say you have 6 people, who each play the game once. 5 people, or 83% of players turn out to be millionaires, and one unlucky person dies. Would you take that bet? Now imagine a slightly different game. Instead, just one person plays, but the same person plays 6 rounds. Still seem like an enticing game?
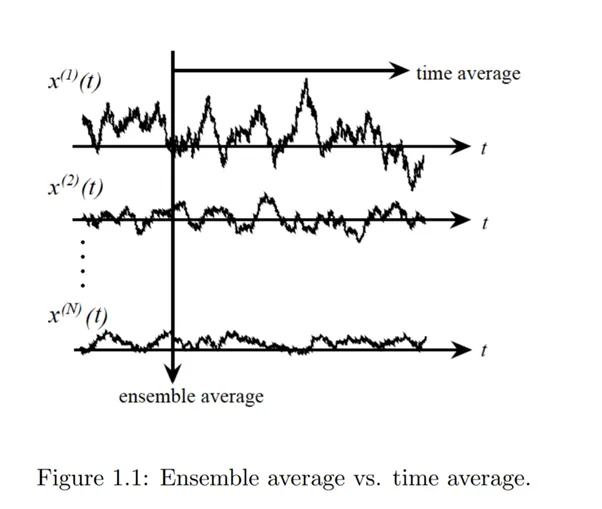
Let’s look at another example. Imagine a game where you roll a die and win or lose money based on the outcome. The rules are: Rolling a 1, 2, or 3: Lose $10. Rolling a 4, 5, or 6: Win $10. What is the time average (i.e. the average of a single player over time)? Say you play the game 100 times and record your winnings. Your time average is the average outcome of your rolls over these 100 games. For example, if the first five roll outcomes are (1,6,3,4,2), your winnings after five rounds would be −$10 + $10 − $10 + $10 − $10 = -$10. After one hundred rounds, your average winnings may differ significantly depending on the sequence of rolls.
What is the ensemble average (i.e. the average over many players at once)? Now imagine 1,000 players each rolling the die once. The ensemble average is the average outcome across all players. If it is a fair die, half the players roll 1, 2, or 3 and lose $10, while the other half roll 4, 5, or 6 and win $10. The ensemble average is (−$10 x 500 + $10 x 500 ) / 1000 = $0.
The key difference being that the ensemble average gives a neutral expectation ($0 in this case), assuming all outcomes occur equally across players. Whereas the time average depends on the specific sequence of rolls for an individual player and may differ from the ensemble average.
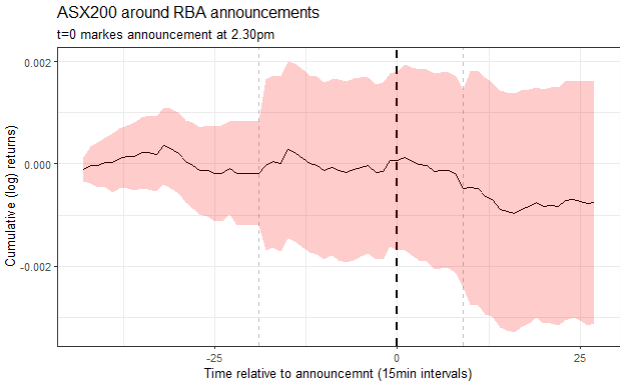
Stock returns also exhibit such non-ergodic behaviour. We can see the impact this has on a portfolio using a simulation in R. The simulation below creates two portfolios and tracks their value over time from time period 0 to time period 100. The initial investment is $100. I generated as list of 100 random returns (from -20% to +20). Both portfolios use the same 100 random returns, but in different orders. The figure below plots one iteration of the value of the portfolios over time:
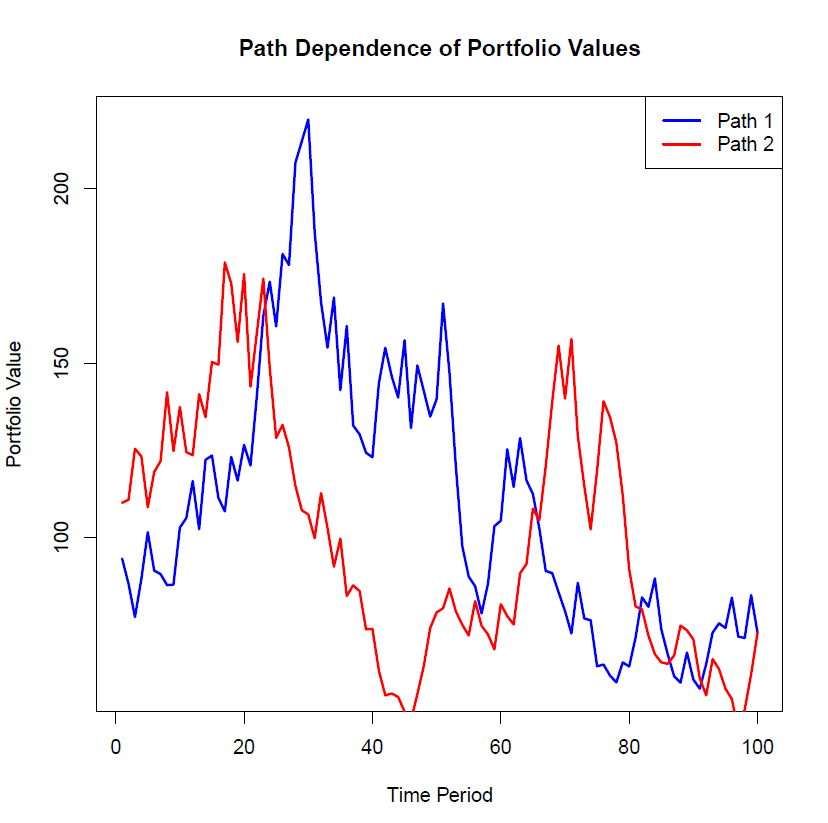
We see the paths of the two portfolios can diverge significantly over time due to differences in the sequence of returns, even when the same set of returns is applied in a different order. If you happen to be retiring in year 50, the performance of your portfolios could vary greatly, leading to vastly different outcomes. This underscores the critical importance of considering sequence-of-returns risk when constructing investment portfolios. Since non-ergodicity penalizes large losses more than it rewards equivalent gains, prioritizing wealth preservation is essential. Safeguarding capital ensures that investors can continue to participate in future growth opportunities.
The code:
# Parameters
n_periods <- 100
initial_investment <- 100
# Simulate two paths of returns
returns_path1 <- runif(n_periods, min = -0.20, max = 0.20) # Random returns between -20% and +20%
returns_path2 <- sample(returns_path1) # Same returns, different order
# Calculate portfolio values over time
portfolio_values_path1 <- cumprod(1 + returns_path1) * initial_investment
portfolio_values_path2 <- cumprod(1 + returns_path2) * initial_investment
# Arithmetic average returns for both paths
arithmetic_avg_path1 <- mean(returns_path1)
arithmetic_avg_path2 <- mean(returns_path2)
# Final portfolio values
final_value_path1 <- tail(portfolio_values_path1, 1)
final_value_path2 <- tail(portfolio_values_path2, 1)
# Output results
cat("Path 1: Final Value =", final_value_path1, "\n")
cat("Path 2: Final Value =", final_value_path2, "\n")
cat("Arithmetic Average Return (Path 1) =", arithmetic_avg_path1, "\n")
cat("Arithmetic Average Return (Path 2) =", arithmetic_avg_path2, "\n")
# Plot the paths
plot(1:n_periods, portfolio_values_path1, type = "l", col = "blue", lwd = 2,
xlab = "Time Period",
ylab = "Portfolio Value",
main = "Path Dependence of Portfolio Values")
lines(1:n_periods, portfolio_values_path2, col = "red", lwd = 2)
legend("topright", legend = c("Path 1", "Path 2"), col = c("blue", "red"), lwd = 2)
#Descriptive
summary(portfolio_values_path1)
summary(portfolio_values_path2)